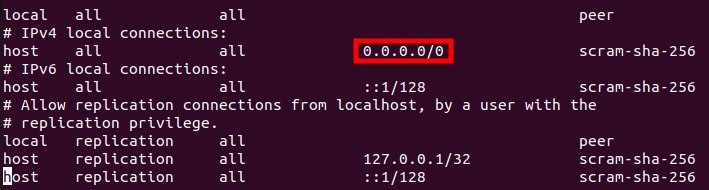
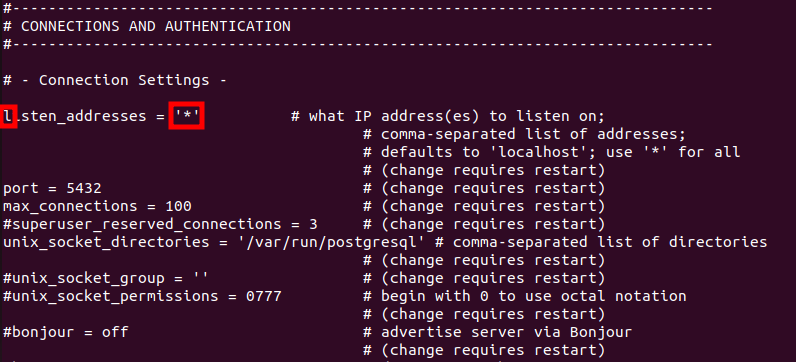
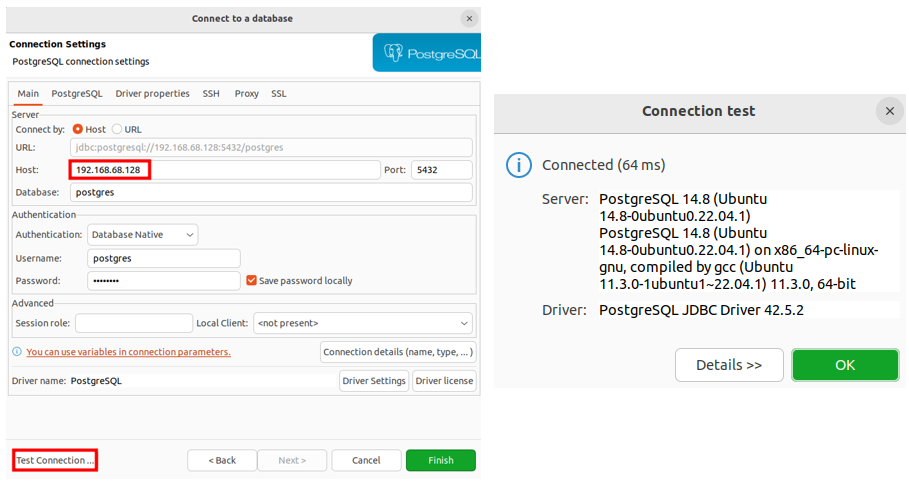
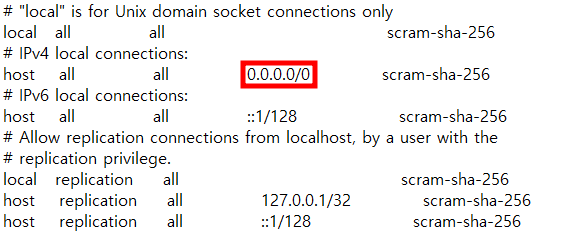
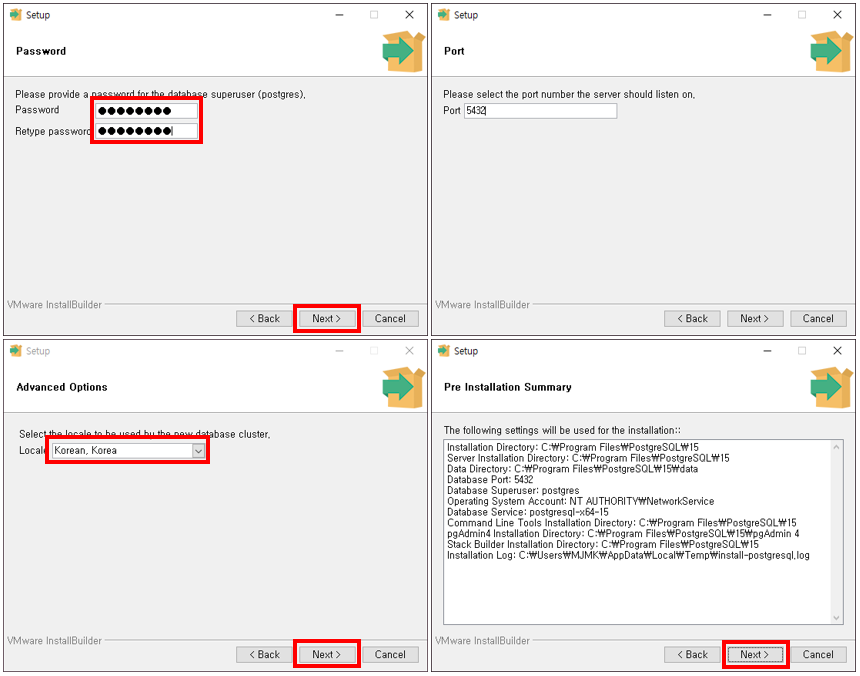
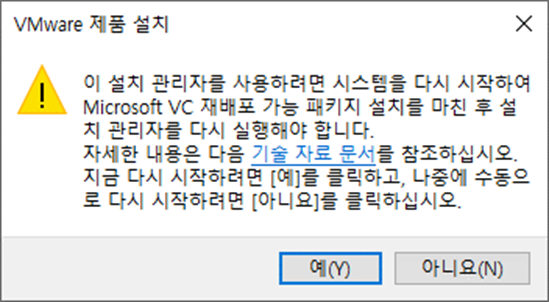
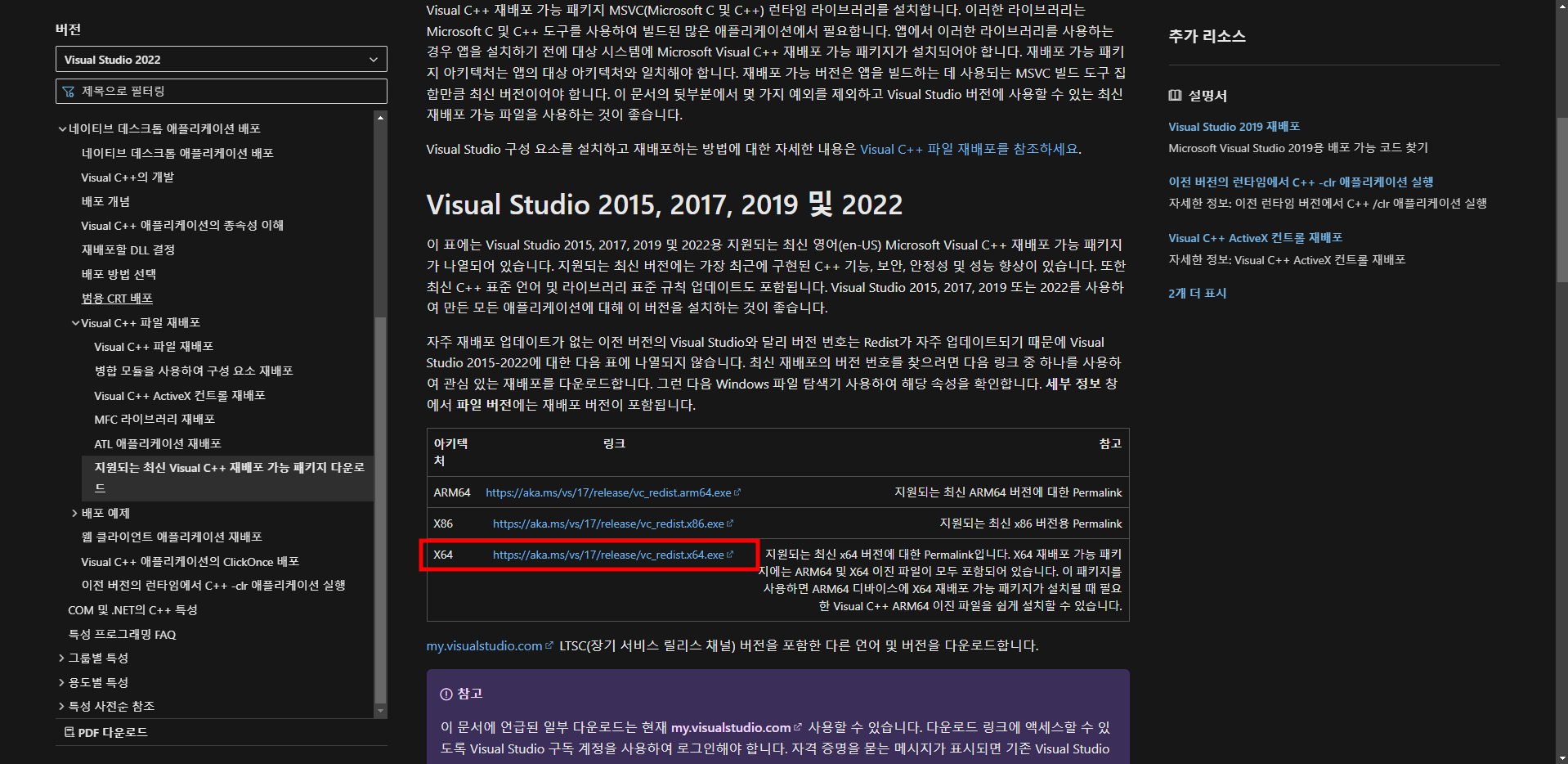
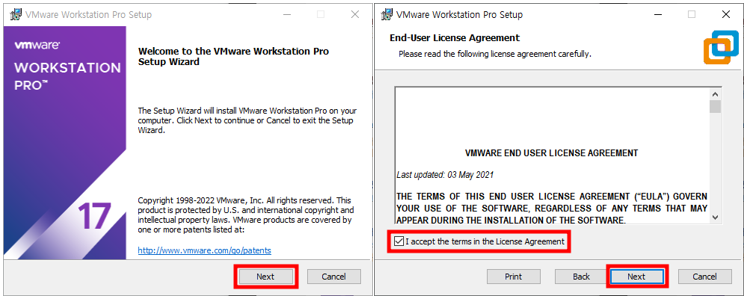
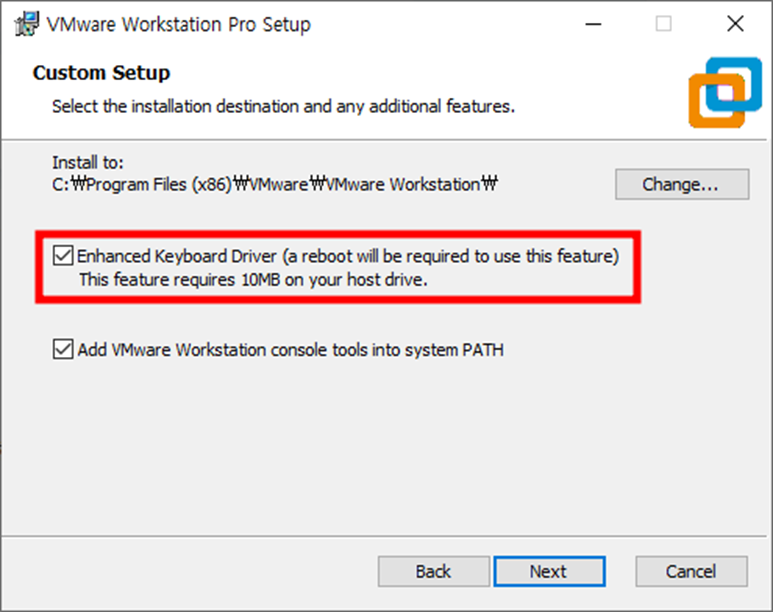
PyCharm으로 Project를 생성 후, 터미널을 통하여 Django App를 생성할 때에는, manage.py를 이용하여 생성하기 때문에 가상환경 경로를 변경해야 한다. (pythonProject2 → pythonProject2/django_project_2) 경로 변경이 번거로울 때, PyCharm에서 자동으로 생성하는 Project를 제거해 보자.
■ 파일 이동 방법
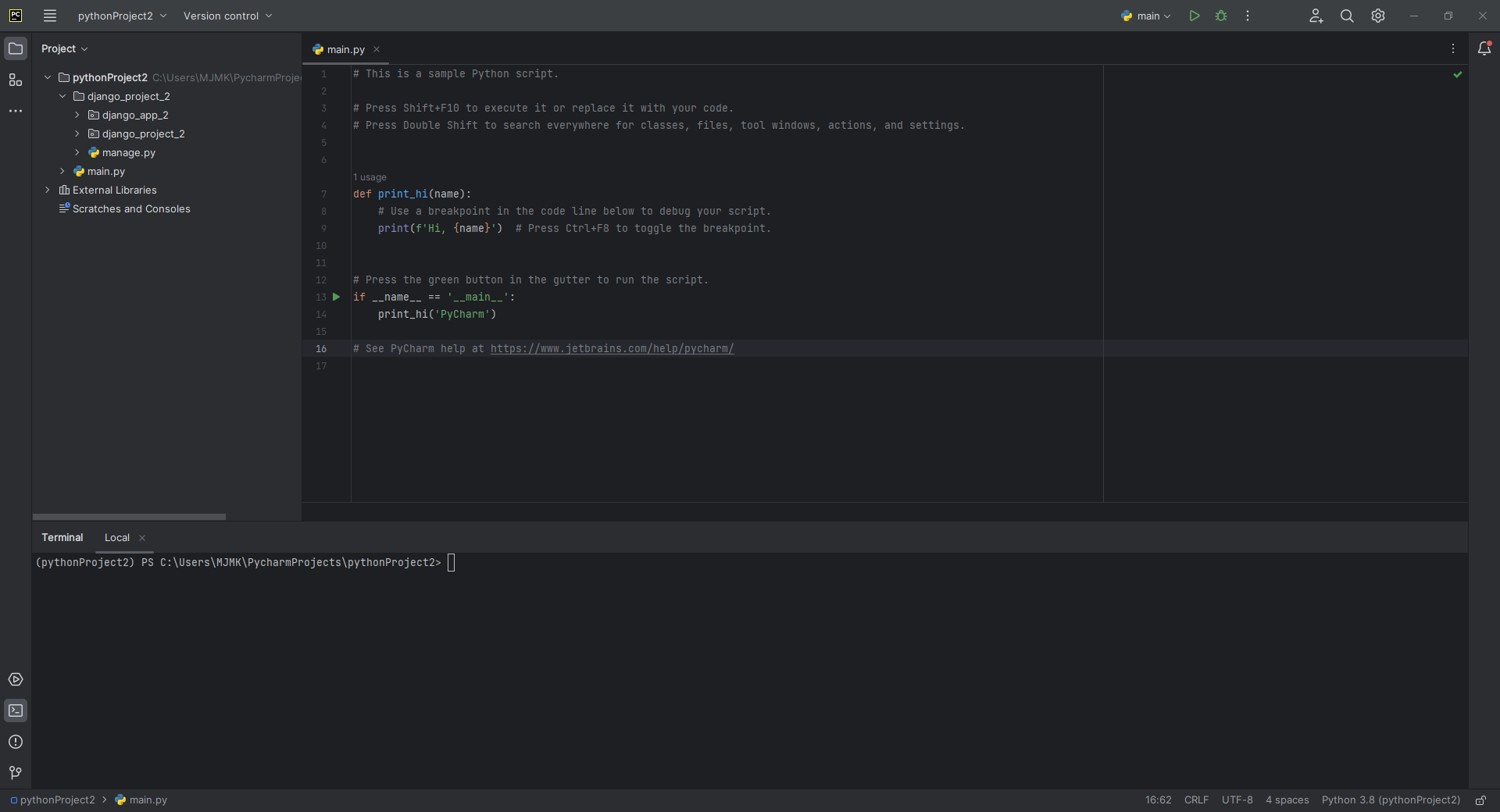
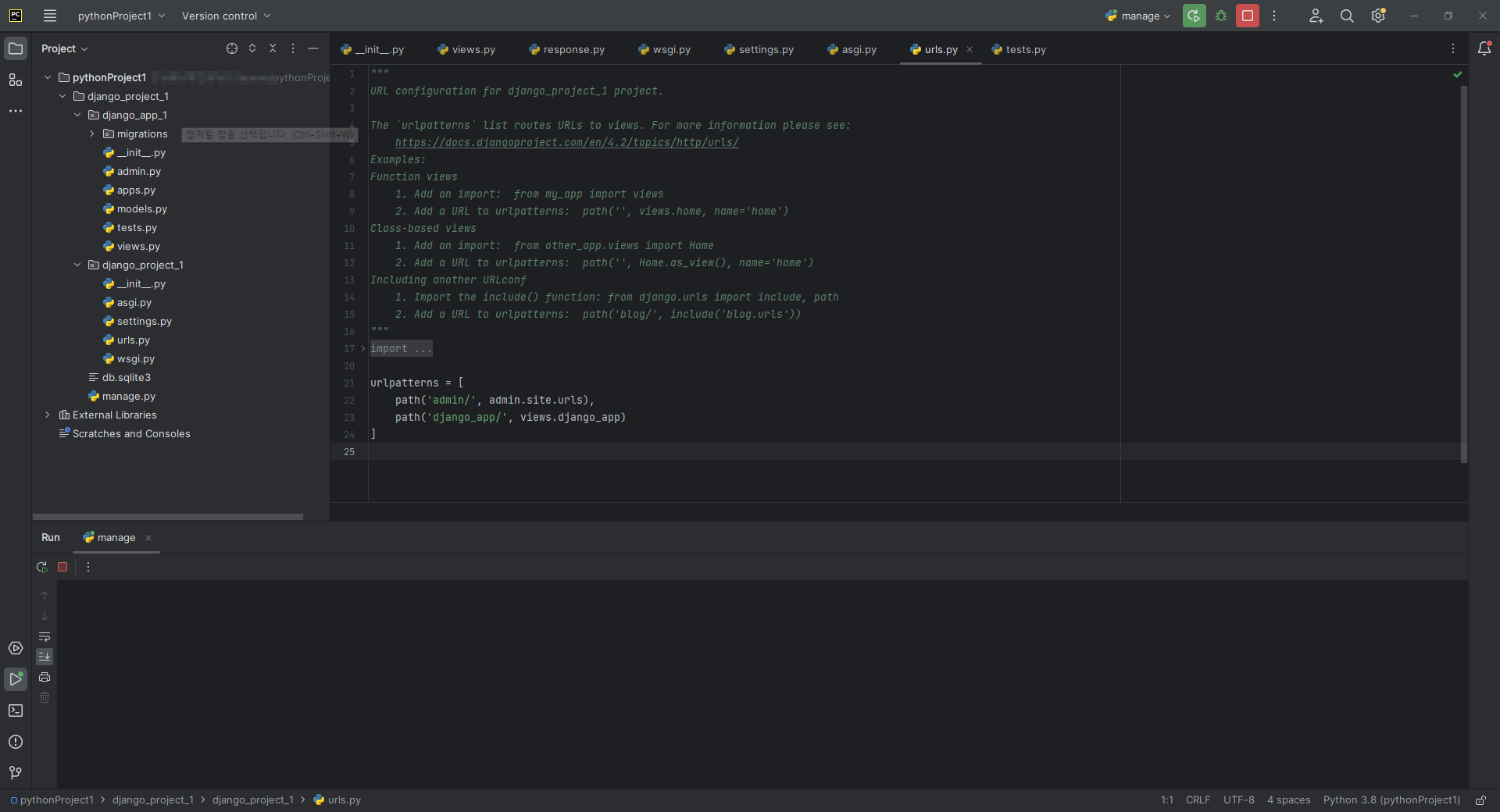
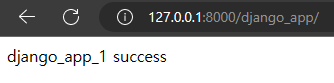
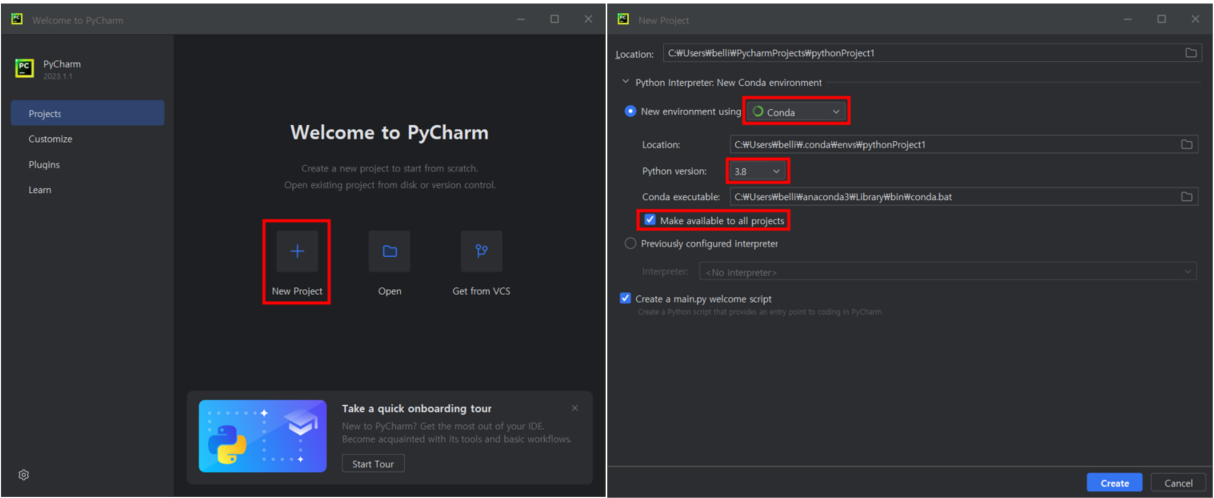
1. PyCharm으로 새 Project를 만들고, Django Project와 App을 만들어놓은 상태이다.(아래 이미지 참고)
2. 실제 파일이 있는 경로로 이동. idea폴더, main파일을 제외하고 원하는 경로로 폴더 및 파일을 이동한다.
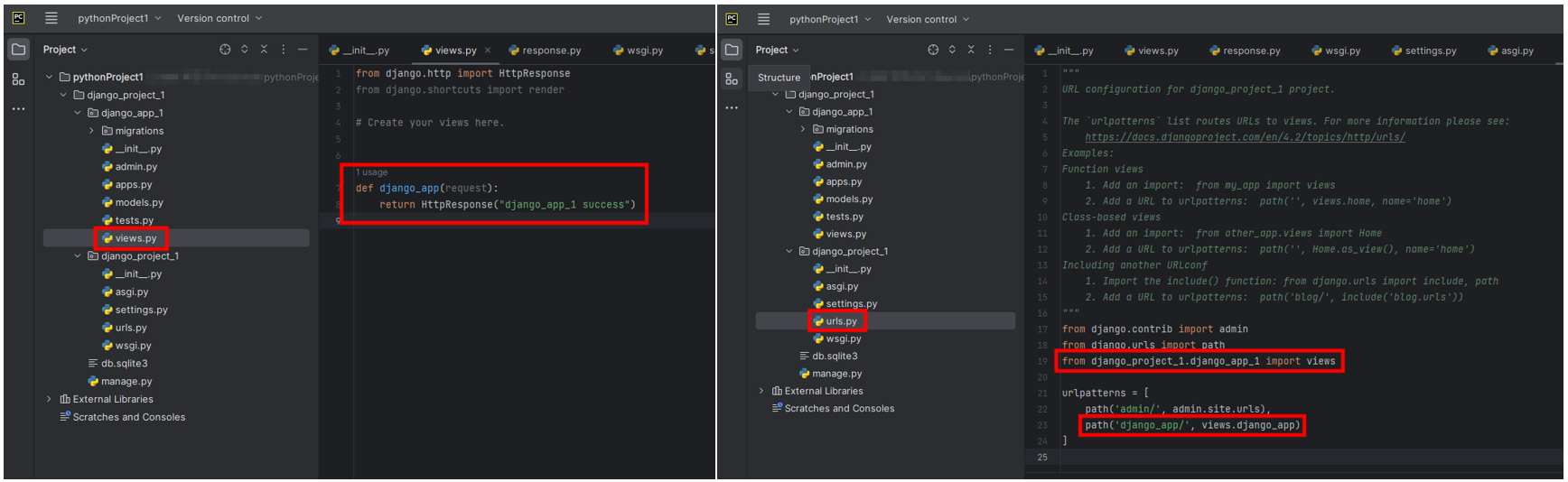
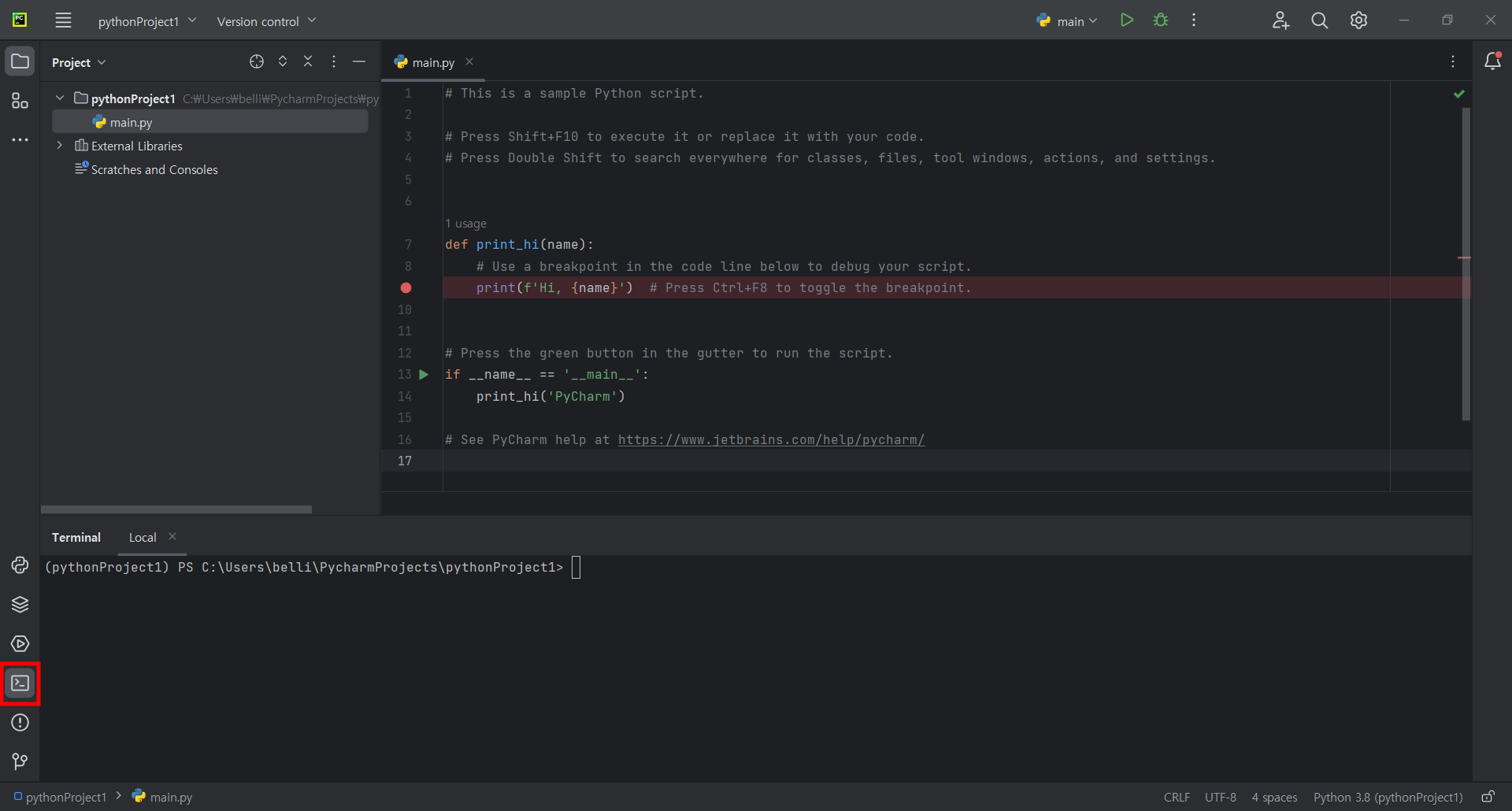
3. PyCharm을 통하여 이동한 경로에 가서 Project를 실행한다.
Project Open 화면
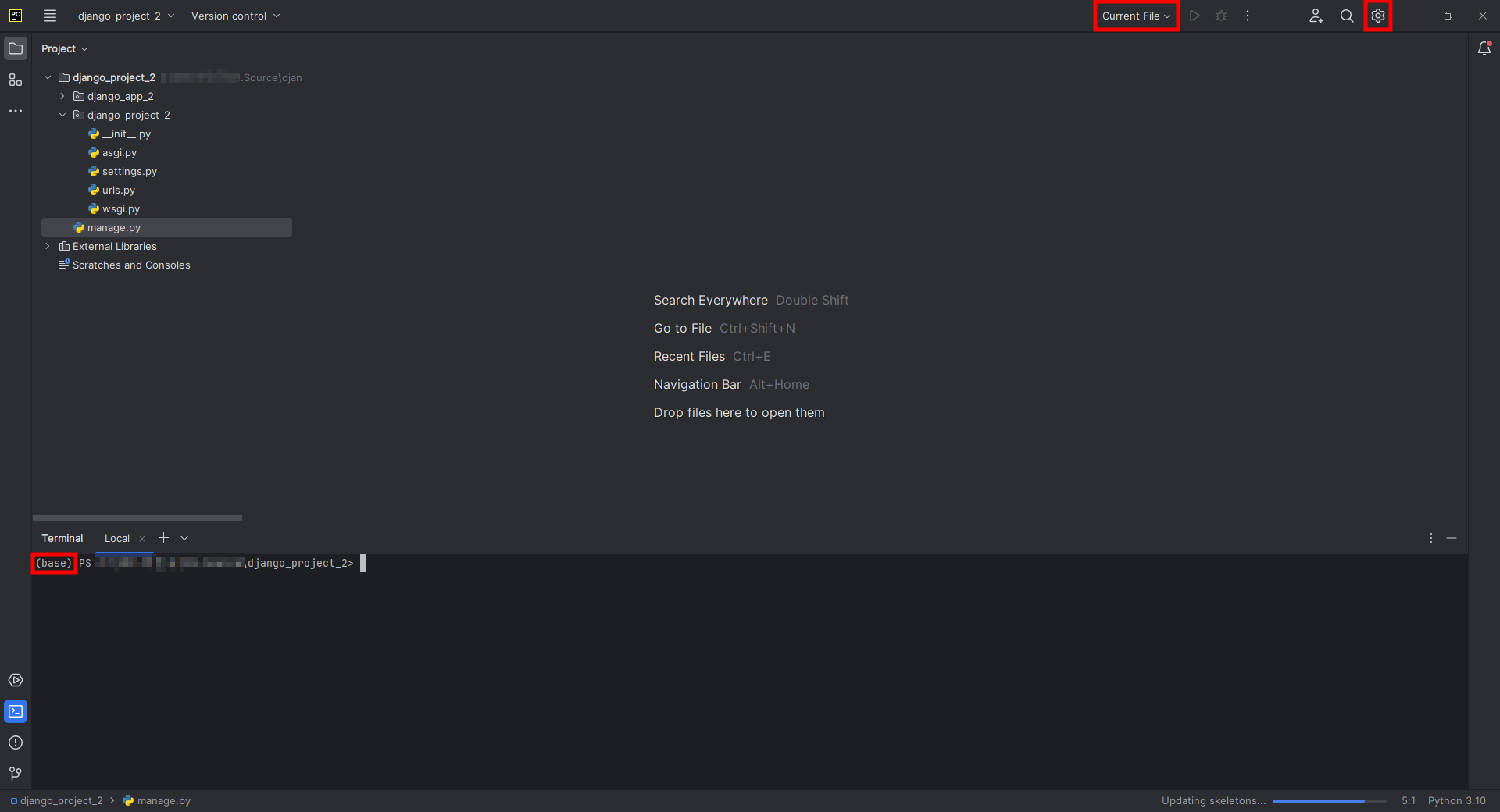
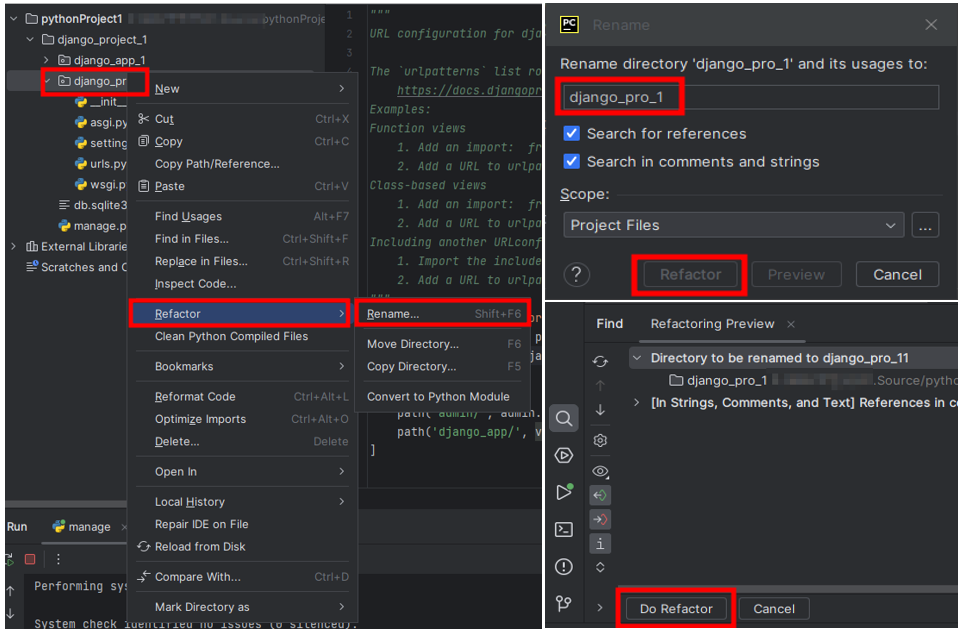
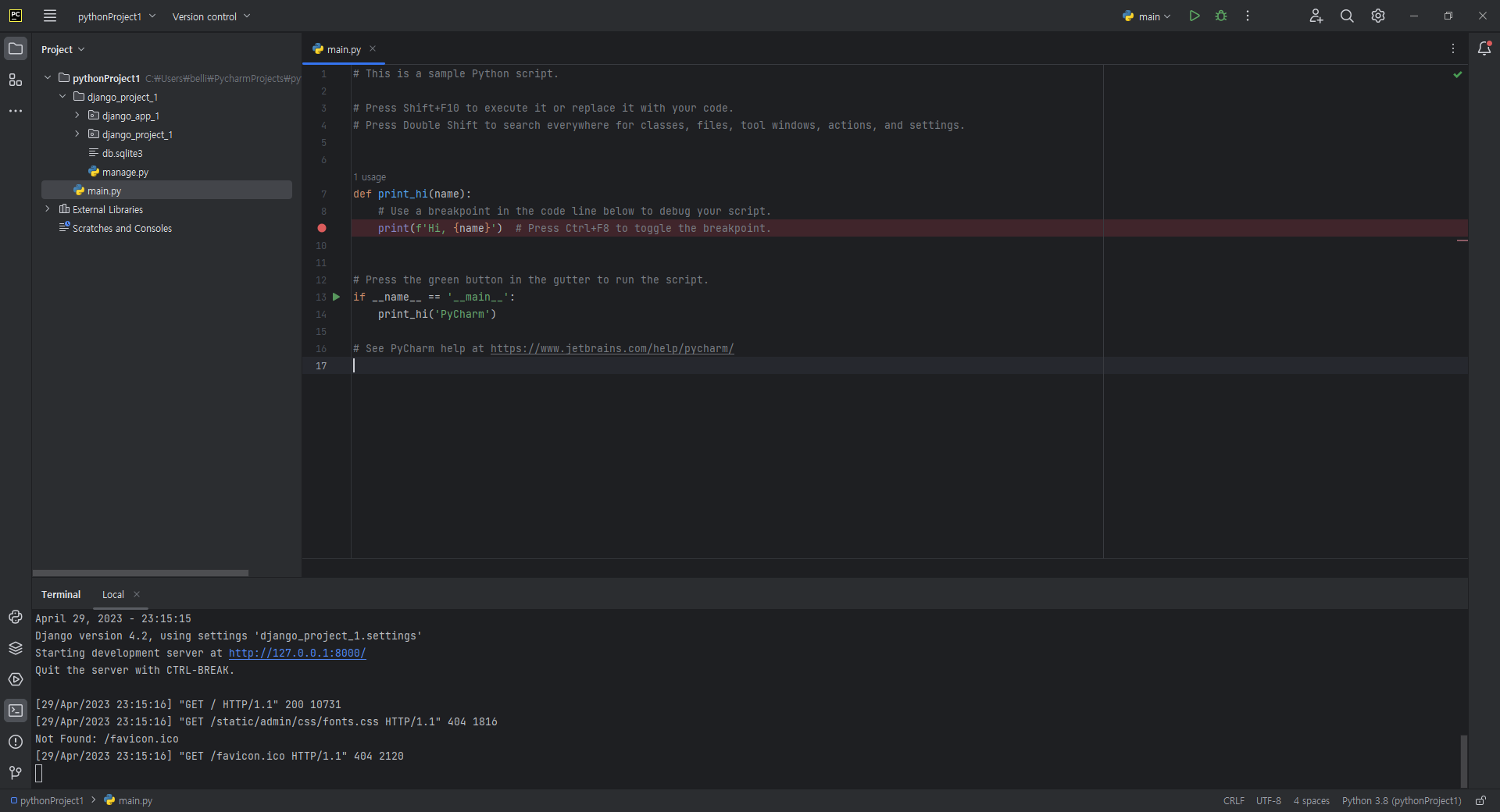
4. Project를 열어보면 pythonProject2 폴더가 사라진 것을 볼 수 있다. 추가적으로 가상환경은 [pythonProject2 → base], configuration은
[main → Current File]로 변경되었다. 이 상태에서 Project를 실행하게 되면 에러가 발생한다.
그럼 이제 변경된 환경에 대하여, Server가 다시 구동되도록 설정해 보도록 하자.
■ 폴더 이동후, Django Server 재설정 방법
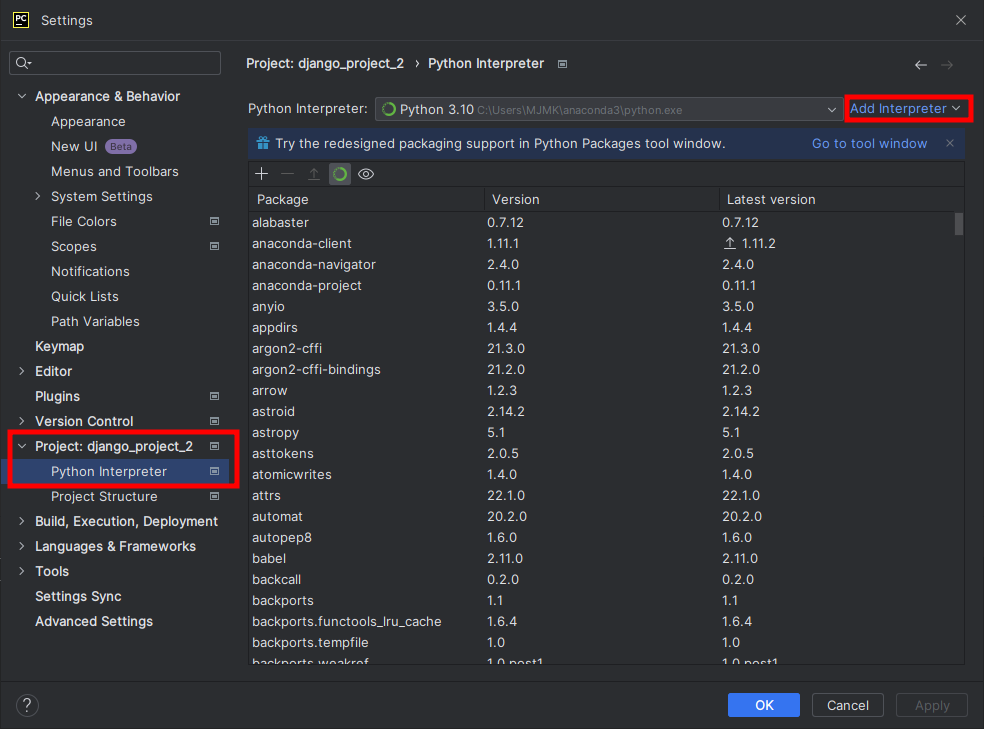
1. PyCharm 우측 위 설정 버튼을 클릭하면 아래와 같은 설정 창이 뜬다.
PyCharm 설정 화면
2. 왼쪽 Project: django_project_2(생성된 Project명) - Python Interpreter를 클릭한다.
3. 우측 위 Add Interpreter를 클릭한다.
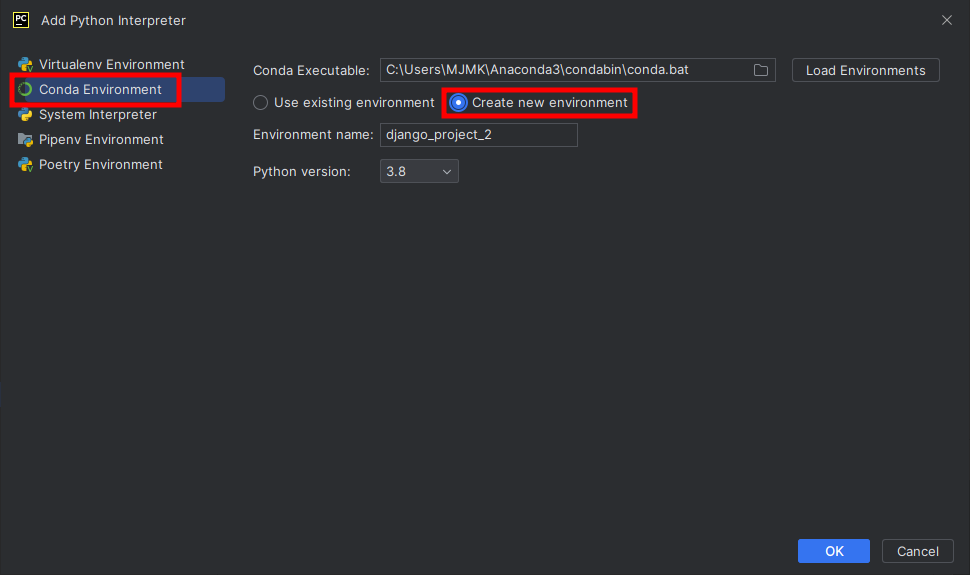
Add Interpreter 설정화면
4. Anaconda를 사용하여 가상환경을 관리하기로 했으므로, Conda Environment - Create new environment를 선택, 나머지는 사용자에 맞게 설정하고 OK버튼을 누른다.
5. PyCharm 상단 Current File을 클릭하여, Python Configuratoin을 추가한다. 추가하는 방법을 모를 때, 아래 링크 참고.
위의 2개만 수정해도 당장은 실행되지만, asgi.py, wsgi.py도 수정을 해야 한다.
(참고) HttpResponse
- 간단하게 설명하자면 urls.py에서 정리된 Url을 요청(Request)하면 응답(Response)이 오는 구조인데, Request는 함수에 첫 번째 인자로 전달하고, Response는 HttpResponse 또는 JsonResponse로 전달받는다. 그렇기 때문에 별도로 Html파일을 만들지 않고도 페이지를 확인할 수 있다.
2. Model(모델), Template(템플릿), View(뷰)로 구성된 MTV 패턴을 사용하고 있다. (MVC 패턴과 유사)
3. SQL을 사용하지 않고 Database에서 사용하는 테이블(RDBMS)을 자동으로 대응해 주는 ORM(Object-Relational Mapping)을 통하여 코드를 작성할 수 있다.
4. 많은 보안 기능을 내장하고 있어, 보안성이 우수하다.
5. 다양한 타사 패키지 및 플러그인을 지원한다.
6. 2023년 Laravel, Ruby on Rails에 이어 3위를 차지할 정도로 인기가 많은 프레임워크이다.
7. 대표적인 사이트의 예로 Instagram, JetBrains 등이 있다.
■ 장점
1. 설치가 간편하다.
2. 포럼, 블로그, 소셜 미디어 등 수많은 개발자 커뮤니티를 가지고 있어 검색 가능할만한 자료가 많다.
3. 다른 프레임워크보다 강력하고 많은 라이브러리를 사용할 수 있다. 그렇기 때문에, 많은 코딩 없이 프로그램을 완성시킬 수 있다. 초보자들도 다가가기 편한 프레임워크다.
4. IDE(통합 개발 환경)가 훌륭하다. (PyCharm, Visual Studio Code 등)
5. 프로젝트를 만들면 별도의 개발 없이 자동으로 관리자 화면을 제공한다.
6. App 단위로 구성이 되어 있어, 독립적으로 작업할 때 매우 쉽다.
7. ORM을 제공하기 때문에 쿼리 없이 데이터를 관리할 수 있다.
8. 많은 보안기능을 제공하고 있으며, 설정에도 매우 간편하다.
9. 웹 서버를 포함하고 있어서 개발과정에 별도로 웹서버가 없어도 된다.
10. 개발과정에서는 소스가 수정되면, 서버를 다시 시작하지 않아도 바로 적용이 된다.
11. Python을 기본으로 개발한다면, Python에서 제공하는 모든 기능을 활용할 수 있다. (Docker 구성 및 API 연계 등)
■ 단점
1. 자료는 많지만, 아직 한글 문서가 많은 편은 아니다.
2. 소형 프로젝트에는 사용하기 무겁고 기능이 많아 부적합하다.
3. 장점에도 소개되었지만, 내부에 구현된 기능이 많다는 것은 곧, 자유롭게 코딩할 수 있는데 한계가 있으므로, 코딩하는데 어려움을 겪을 수 도 있다. 또한 Django에서 문제가 생겼을 때, Python코딩으로 문제를 해결하는 경우가 발생할 수 있다.
4. ORM을 사용한다고 했을 때, 복잡한 데이터 구조(Join이 많은 경우)나 Procedure(프로시져)를 많이 사용한 곳에는 적합하지 않을 수 있다.
5. Python의 단점을 그대로 가져온다. (Python은 타입을 선언하지 않아도 실행되기에, 타입을 검사하려면 시간이 걸릴 수밖에 없다. 또한, 인터프리터 언어(한 줄씩 읽어 내려가며 실행하는 언어)이기 때문에 상대적으로 컴파일하는 프로그램보다 편하지만 빠르지는 않다.)
■ Django(장고)를 선택한 이유
1. Python에서 제공하는 모든 기능을 활용할 수 있다.
2. Django는 Python을 기반으로 만들어진 프레임워크이기 때문에, AI(인공지능) 개발에 유용하다.