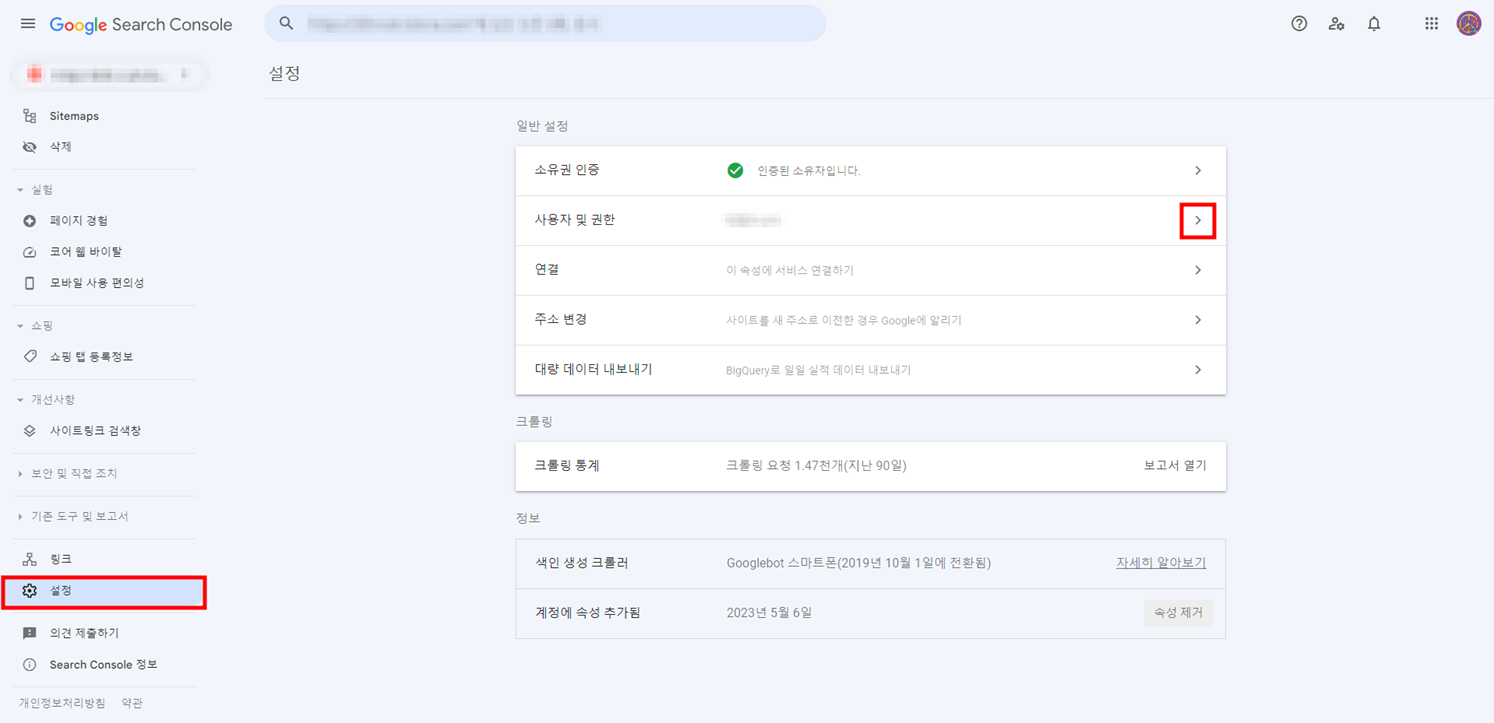
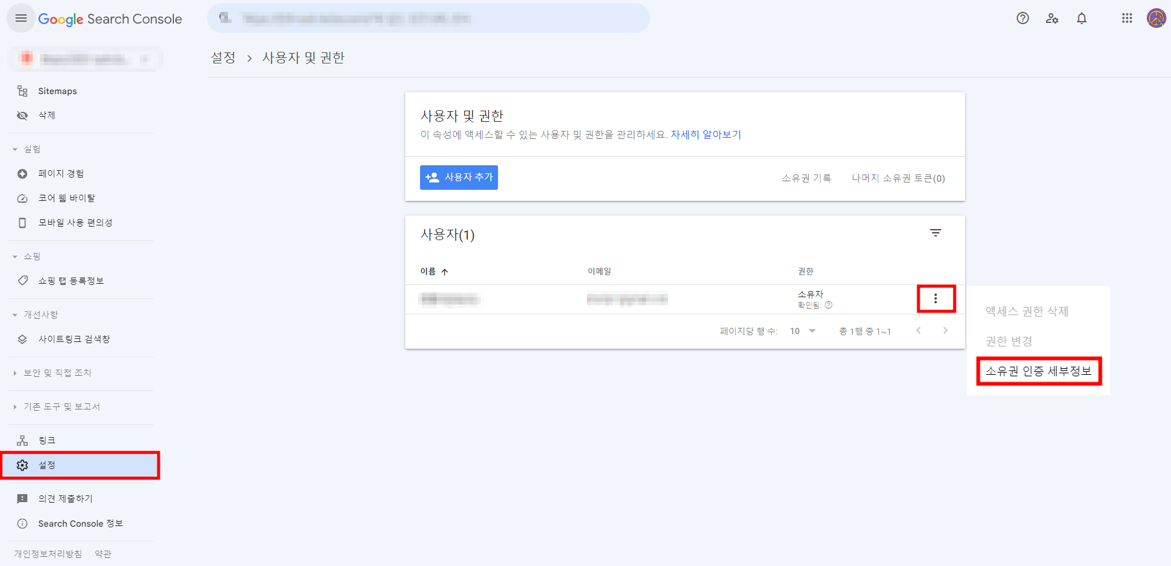
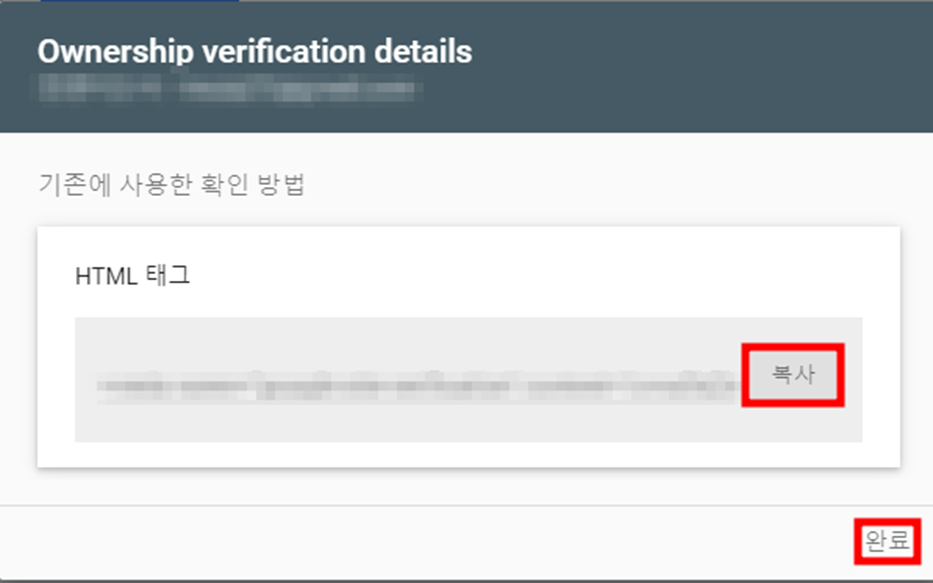
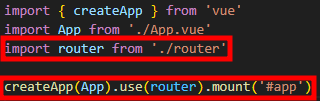
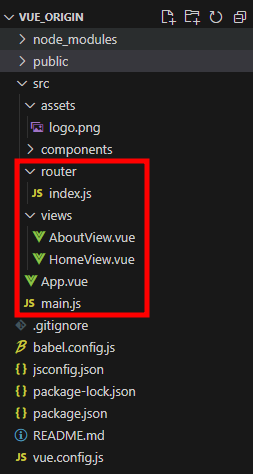
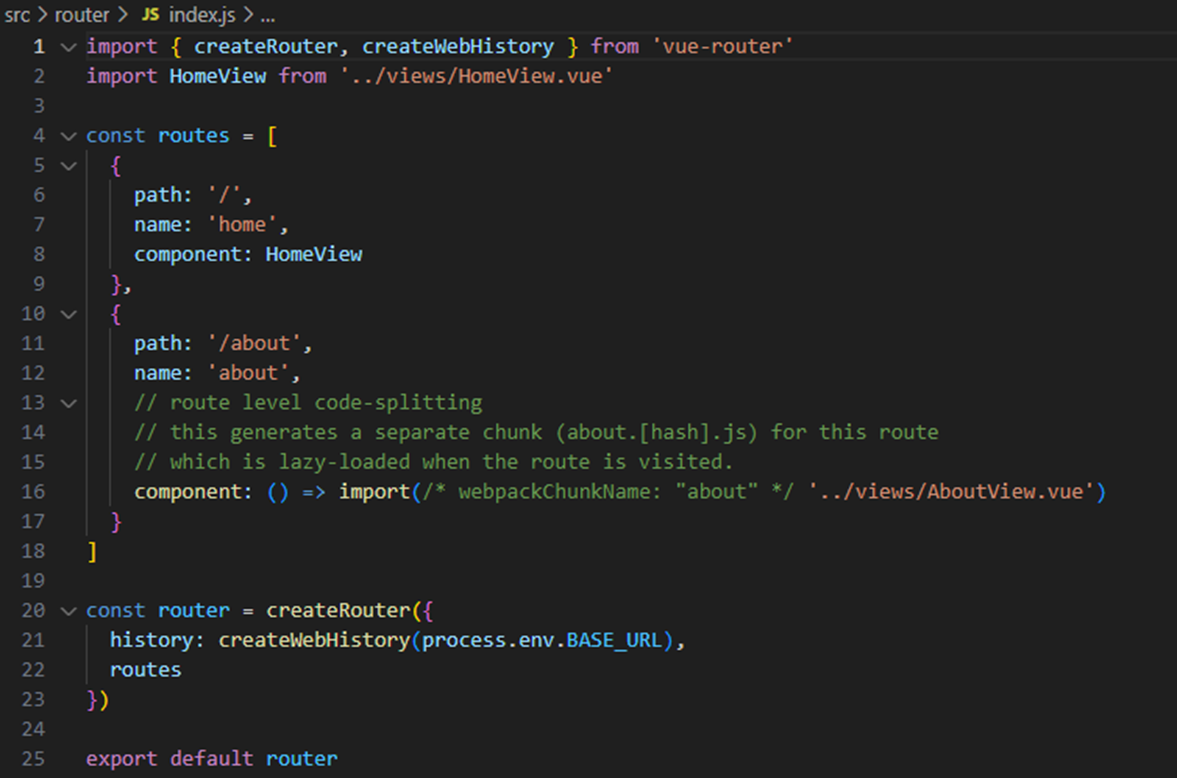
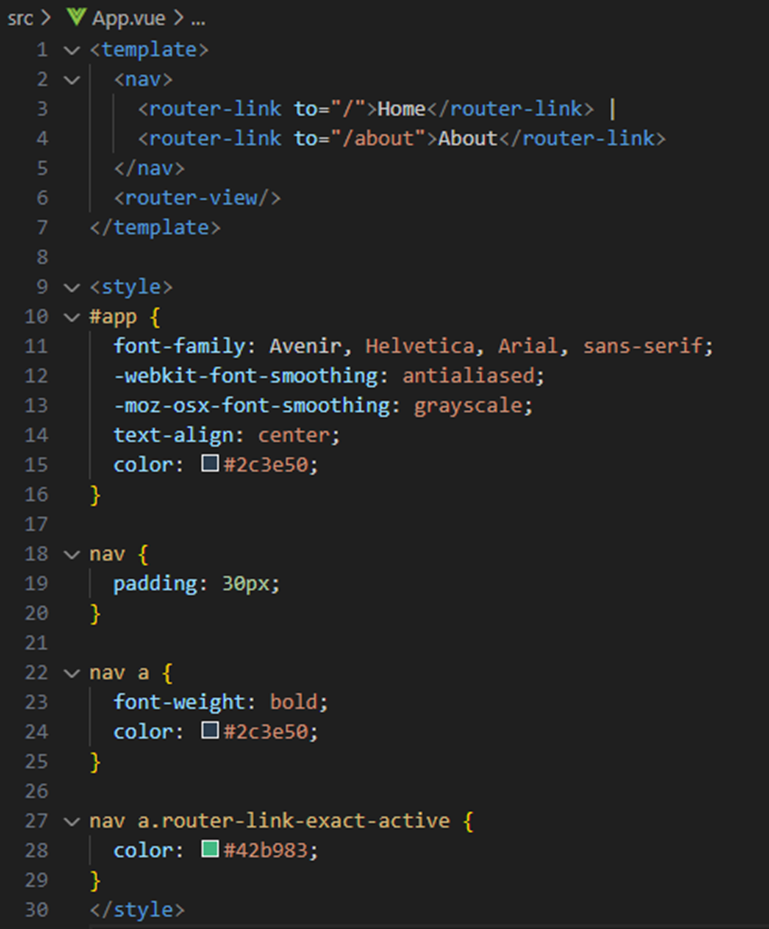
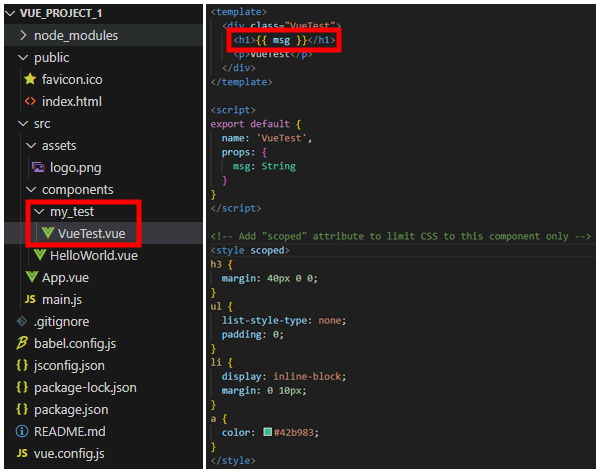
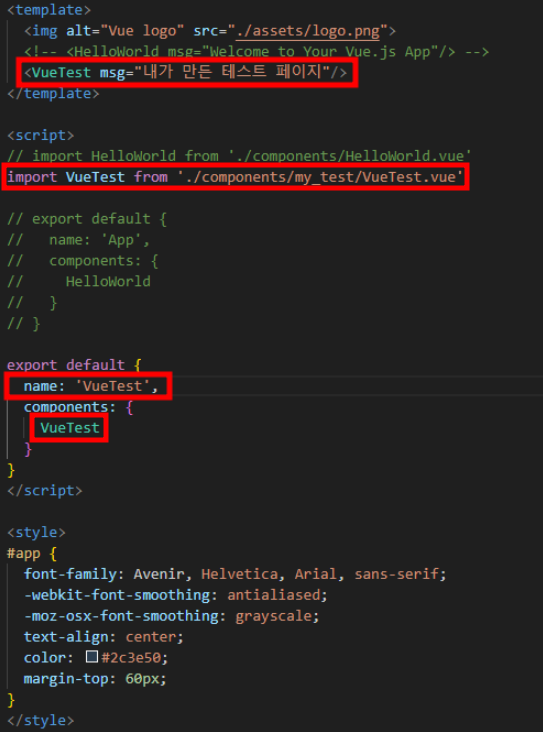
1. debootstrap
- Debian 기반 리눅스 시스템을 설치하고 구성하기 위한 도구이다. 주로 Debian 및 Debian 계열 배포판 (예: Ubuntu)에서 사용된다.
Debootstrap를 사용하면 최소한의 시스템 파일 및 패키지를 포함하는 Debian 루트 파일 시스템을 생성하고,
이를 사용하여 사용자 정의 된 시스템을 구축할 수 있다.
2. upstart
- 초기화 및 서비스 관리를 위한 리눅스 시스템 초기화 시스템이다.
이전에 init 시스템이나 sysvinit 시스템과 호환성을 가지며, 더욱 빠르고 효율적인 부팅 및 서비스 관리를 제공하기 위해 개발되었다.
Upstart은 Ubuntu와 같은 일부 리눅스 배포판에서 기본 초기화 시스템으로 사용되었다.
3. nginx
- 오픈 소스 웹 서버 및 리버스 프록시 서버 소프트웨어로, 웹 애플리케이션을 제공하고 관리하는 데 사용된다.
Nginx는 빠르고 가벼우며 확장 가능하며, 대규모 웹 사이트 및 애플리케이션을 위한 고성능 웹 서버로 널리 사용된다.
또한 Nginx는 부하 분산, SSL/TLS 종단 간 암호화, 캐싱, 로드 밸런싱, 보안 및 웹 애플리케이션 방화벽과 같은 고급 기능을 제공한다.
4. squid
- 오픈 소스로 개발된 프록시 서버 소프트웨어로, 네트워크에서 웹 콘텐츠를 캐싱하고 필터링하는 데 사용된다.
Squid는 대부분의 운영 체제에서 동작하며, 네트워크의 트래픽을 줄이고 사용자 경험을 향상시키는 데 도움을 준다.
5. cortex
- 오픈 소스로 개발된 시계열 데이터 처리 및 분석 플랫폼이다.
Cortex는 PromQL 쿼리 언어와 호환되며, Prometheus와 통합하여 대규모 시계열 데이터를 수집, 저장, 검색 및 시각화하는 데 사용된다.
Cortex는 효율적인 확장성, 고성능, 그리고 신뢰성을 제공하여 대규모 시계열 데이터의 처리를 지원한다.
6. apache2
- Apache HTTP Server, 더 알려진 이름으로 Apache는 가장 널리 사용되는 오픈 소스 웹 서버 소프트웨어 중 하나이다.
Apache는 다양한 운영 체제에서 동작하며, 정적 및 동적 웹 페이지를 서비스하는 데 사용된다.
또한 Apache는 모듈 아키텍처를 통해 다양한 기능을 확장할 수 있어 많은 웹 개발자와 시스템 관리자에게 인기가 있다.
7. kafka
- Apache Kafka는 분산 스트리밍 플랫폼으로, 대용량 실시간 데이터 스트림을 처리하고 저장하는 데 사용되는 오픈 소스 소프트웨어다.
Kafka는 이벤트 스트리밍 아키텍처(ESA)의 핵심 요소로 사용되며, 대부분의 시스템에서 로그 및 이벤트 데이터를 신뢰성 있게 수집,
전송 및 처리하는 데 사용된다.
8. mysql
- 오픈 소스 관계형 데이터베이스 관리 시스템(RDBMS)으로, 데이터베이스를 생성, 관리, 및 쿼리 하기 위한 소프트웨어다.
MySQL은 많은 웹 응용 프로그램, 비즈니스 애플리케이션, 데이터 웨어하우스, 온라인 서비스 등 다양한 응용 분야에서 널리 사용되고 있으며,
빠른 성능, 안정성, 확장 가능성을 제공한다.
9. bind9
- 오픈 소스로 개발된 DNS(Domain Name System) 서버 소프트웨어다.
DNS는 인터넷에서 도메인 이름과 IP 주소를 연결하고, 네트워크에서 호스트 및 서비스를 검색하는 데 사용되는 핵심 인프라 서비스다.
BIND9는 DNS 쿼리에 대한 응답을 생성하고 DNS 데이터를 저장하고 유지 관리하는 서버 역할을 수행한다.
10. zookeeper
- 분산 응용 프로그램 및 서비스의 조정, 구성 관리, 네임스페이스 및 실시간 모니터링을 위한 분산 서비스이다.
주로 대규모 분산 시스템의 일관성과 동기화를 달성하기 위해 사용된다.
ZooKeeper는 Apache 소프트웨어 재단에서 개발 및 관리하며, 오픈 소스로 제공된다.
11. prometheus
- 오픈 소스 시스템 및 응용 프로그램 모니터링 및 경고 도구다. 이는 기본적으로 컨테이너화된 환경 및 분산 시스템에서 사용하기에 적합하며,
대규모 환경에서 실시간으로 시스템 및 애플리케이션의 상태를 모니터링하고 경고를 생성하는 데 사용된다.
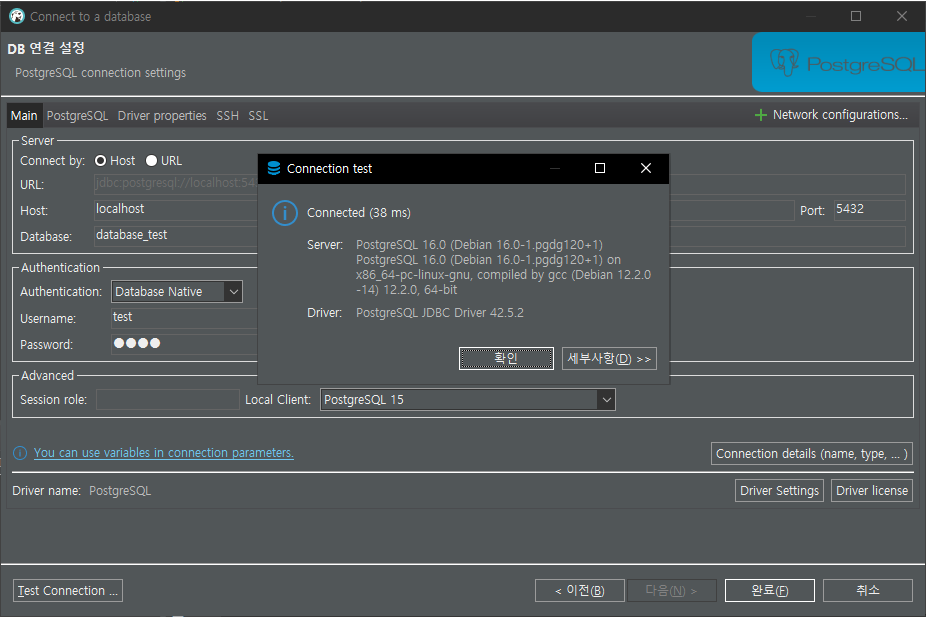
12. postgres
- 오픈 소스 객체 관계형 데이터베이스 관리 시스템(RDBMS)이다.
PostgreSQL은 신뢰성 높은 데이터베이스 관리, 고급 기능, 확장 가능성 및 데이터 무결성을 제공하며, 무료로 사용할 수 있는 소프트웨어다.
많은 기업 및 개발자 커뮤니티에서 널리 사용되며, 대규모 웹 애플리케이션, 비즈니스 시스템, 데이터 웨어하우스 등 다양한 응용 분야에서
활용된다.
13. redis
- Remote Dictionary Server의 약자로 오픈 소스인 메모리 데이터 스토어다. 키-값 쌍을 저장하고 검색하는 데 사용된다.
Redis는 고성능 및 대용량 데이터를 처리하기 위해 설계되었으며, 다양한 응용 프로그램에서 캐싱, 세션 관리, 메시지 브로커 및 데이터베이스로
사용된다.
14. grafana
- 오픈 소스 데이터 시각화 및 모니터링 도구로, 다양한 데이터 소스로부터 데이터를 가져와 시각적으로 표현하고 모니터링하는 데 사용된다.
Grafana는 다양한 시각화 패널 및 대시보드를 제공하여 데이터를 실시간으로 모니터링하고 분석하는 데 도움을 준다.
15. memcached
- 분산 메모리 캐싱 시스템으로, 데이터베이스, API 호출 또는 기타 데이터 소스에서 가져온 데이터를 메모리에 캐시 하여 빠르게 액세스 할 수
있도록 하는 역할을 한다.
Memcached는 오픈 소스이며, 빠른 데이터 조회와 검색 성능을 필요로 하는 웹 애플리케이션 및 분산 시스템에서 많이 사용된다.
16. dotnet-aspnet
- ASP.NET은 .NET을 사용하여 최신 웹 앱 및 서비스를 구축하기 위해 Microsoft에서 만든 오픈 소스 웹 프레임워크다.
17. dotnet-deps
- 종속성을 검사하고 업데이트한다.
18. prometheus-alertmanager
- Prometheus 모니터링 시스템과 함께 사용되는 알림 관리 도구다.
Prometheus는 시스템 및 애플리케이션 모니터링을 위한 오픈 소스 도구로, 서버 및 애플리케이션의 상태를 주기적으로 스크랩하고 이벤트에
대한 경고 및 알림을 생성한다.
Alertmanager는 이러한 경고 및 알림을 수신하고 관리하며, 사용자에게 경고를 전달하고 필요한 조치를 취할 수 있도록 도와준다.
19. dotnet-runtime
- Microsoft에서 개발한 .NET 프레임워크의 일부다.
.NET 프레임워크는 다양한 프로그래밍 언어를 지원하고, Windows 운영 체제에서 실행되는 애플리케이션 개발을 위한 플랫폼으로 사용된다.
.NET Runtime은 .NET 애플리케이션을 실행하기 위한 런타임 환경을 제공한다.
20. cassandra
- 분산형 NoSQL 데이터베이스 시스템의 하나로, 대량의 데이터를 고성능으로 저장하고 관리할 수 있는 오픈 소스 솔루션이다.
아파치 소프트웨어 재단(Apache Software Foundation)에서 개발하고 유지보수하며, 빅데이터 및 대규모 웹 애플리케이션에서 많이 사용된다.
21. jre
- Java 프로그램을 실행하기 위한 환경을 제공하는 소프트웨어다.
JRE는 Java 언어로 작성된 애플리케이션 및 애플릿(웹 페이지에서 실행되는 작은 Java 프로그램)을 실행하는 데
필요한 모든 런타임 컴포넌트와 라이브러리를 포함하고 있다.